


机器翻译的几代发展历史
2019-08-13 08:00来自翻译狗阅读15
机器翻译是自然语言处理领域的皇冠明珠。机器翻译历史与计算机的发展历史差不多悠久,计算机诞生的时候,机器翻译是人们首先想到的应用之一。1949年美国数学家、洛克菲勒基金会自然科学部门的负责人Warren Weaver发表了一份《翻译》备忘录,开启了机器翻译研究的历史性一页。
机器翻译技术的发展可以分为三个发展阶段
最早的机器翻译系统基于情报学中的“加密/解密”技术,但以失败告终;随后的机器翻译系统开发采用语言学家手工书写翻译规则,计算机专家编程实现的方式。但是,基于规则的方法只能正确翻译那些满足人工规则的句子,但对不符合之前写过的规则的句子,这种方法就无能为力了。人工书写翻译规则的代价很高,而且翻译规则千变万化,很容易产生规则相互冲突的“跷跷板”现象。翻译记忆技术和基于实例的技术非常依赖于预定义的翻译库,有点死记硬背不灵活。第一代基于规则的机器翻译技术被我国著名的机器翻译专家董振东老师称之为“傻子型”。
 第二代机器翻译技术是基于统计的机器翻译技术。简单来说,统计机器翻译的基本思想是利用机器学习方法,通过对大量的平行语料进行统计分析,构建机器翻译模型。它将源语句子分解为词汇/短语片段,找到这些词汇/短语片段的目标语译文,然后将这些译文进行组合,选择其中模型认为最好的一个译文作为机器翻译结果。这种技术生成的翻译结果,质量非常不稳定,有时候非常完美,有时候非常糟糕,让人不可琢磨,所以被董老师称之为“疯子型”。
第二代机器翻译技术是基于统计的机器翻译技术。简单来说,统计机器翻译的基本思想是利用机器学习方法,通过对大量的平行语料进行统计分析,构建机器翻译模型。它将源语句子分解为词汇/短语片段,找到这些词汇/短语片段的目标语译文,然后将这些译文进行组合,选择其中模型认为最好的一个译文作为机器翻译结果。这种技术生成的翻译结果,质量非常不稳定,有时候非常完美,有时候非常糟糕,让人不可琢磨,所以被董老师称之为“疯子型”。
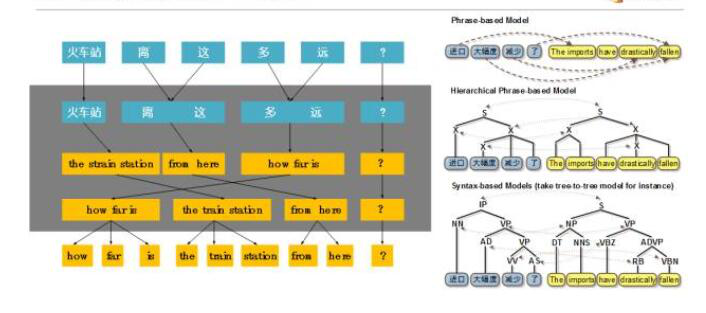 第三代机器翻译技术,也就是基于深度学习技术的机器翻译技术(神经机器翻译,NMT)。深度学习技术通过多个非线性处理单元,能够自动对数据进行表征学习,本质上是一个强大的函数拟合器。目前深度学习已经在图像、语音、自然语言处理等领域取得了空前的成功。从2013年神经机器翻译的提出,2016年10月份谷歌神经机器翻译GNMT系统正式上线,预示NMT的彻底爆发,仅仅用了不到四年的时间。我们小牛翻译去年12月上线了NMT系统,从今年上半年开始国内一些互联网巨头也不断上线了NMT系统,预示着NMT技术框架成为了目前机器翻译的主流技术。
NMT采用经典的编码器-解码器架构,编码器将输入的源语言句子表示为实数向量,解码器根据源语言编码的结果,生成目标语译文。其优点在于模型中考虑了双语句子内部的上下文信息,使生成译文的结构非常流畅。传统的NMT采用循环神经网络(Recurrent Neural Network, RNN)分别作为编码器和解码器。RNN的基本思想是当前时刻的状态受之前时刻的影响,因此理论上具有捕获全局上下文的能力,十分适合对变长的序列建模。在实际应用时,为了缓解RNN固有的梯度消失(Vanishing Gradient)问题,往往使用RNN的两个变种:长短时记忆网络(LSTM),门控循环单元(GRU)。但是RNN网络由于前后时刻存在时序上的依赖(即前一个时刻结束了,才能进行下一个时刻),因此无法并行计算,训练的时间代价很高。
以上就是机器翻译的三代的发展历史,技术的越来越先进。可以让机器翻译结果不断更好地满足用户的应用需求。通过学术界与企业界的联手推动,学术界注重机器翻译理论和技术创新,产业界侧重于机器翻译产品和应用创新,我们有充足的理由相信,当前机器翻译产业化正在迎来发展高潮,通过机器翻译帮助全球语言交流无障碍的时机已经来临。
第三代机器翻译技术,也就是基于深度学习技术的机器翻译技术(神经机器翻译,NMT)。深度学习技术通过多个非线性处理单元,能够自动对数据进行表征学习,本质上是一个强大的函数拟合器。目前深度学习已经在图像、语音、自然语言处理等领域取得了空前的成功。从2013年神经机器翻译的提出,2016年10月份谷歌神经机器翻译GNMT系统正式上线,预示NMT的彻底爆发,仅仅用了不到四年的时间。我们小牛翻译去年12月上线了NMT系统,从今年上半年开始国内一些互联网巨头也不断上线了NMT系统,预示着NMT技术框架成为了目前机器翻译的主流技术。
NMT采用经典的编码器-解码器架构,编码器将输入的源语言句子表示为实数向量,解码器根据源语言编码的结果,生成目标语译文。其优点在于模型中考虑了双语句子内部的上下文信息,使生成译文的结构非常流畅。传统的NMT采用循环神经网络(Recurrent Neural Network, RNN)分别作为编码器和解码器。RNN的基本思想是当前时刻的状态受之前时刻的影响,因此理论上具有捕获全局上下文的能力,十分适合对变长的序列建模。在实际应用时,为了缓解RNN固有的梯度消失(Vanishing Gradient)问题,往往使用RNN的两个变种:长短时记忆网络(LSTM),门控循环单元(GRU)。但是RNN网络由于前后时刻存在时序上的依赖(即前一个时刻结束了,才能进行下一个时刻),因此无法并行计算,训练的时间代价很高。
以上就是机器翻译的三代的发展历史,技术的越来越先进。可以让机器翻译结果不断更好地满足用户的应用需求。通过学术界与企业界的联手推动,学术界注重机器翻译理论和技术创新,产业界侧重于机器翻译产品和应用创新,我们有充足的理由相信,当前机器翻译产业化正在迎来发展高潮,通过机器翻译帮助全球语言交流无障碍的时机已经来临。
第二代机器翻译技术是基于统计的机器翻译技术。简单来说,统计机器翻译的基本思想是利用机器学习方法,通过对大量的平行语料进行统计分析,构建机器翻译模型。它将源语句子分解为词汇/短语片段,找到这些词汇/短语片段的目标语译文,然后将这些译文进行组合,选择其中模型认为最好的一个译文作为机器翻译结果。这种技术生成的翻译结果,质量非常不稳定,有时候非常完美,有时候非常糟糕,让人不可琢磨,所以被董老师称之为“疯子型”。
第三代机器翻译技术,也就是基于深度学习技术的机器翻译技术(神经机器翻译,NMT)。深度学习技术通过多个非线性处理单元,能够自动对数据进行表征学习,本质上是一个强大的函数拟合器。目前深度学习已经在图像、语音、自然语言处理等领域取得了空前的成功。从2013年神经机器翻译的提出,2016年10月份谷歌神经机器翻译GNMT系统正式上线,预示NMT的彻底爆发,仅仅用了不到四年的时间。我们小牛翻译去年12月上线了NMT系统,从今年上半年开始国内一些互联网巨头也不断上线了NMT系统,预示着NMT技术框架成为了目前机器翻译的主流技术。
NMT采用经典的编码器-解码器架构,编码器将输入的源语言句子表示为实数向量,解码器根据源语言编码的结果,生成目标语译文。其优点在于模型中考虑了双语句子内部的上下文信息,使生成译文的结构非常流畅。传统的NMT采用循环神经网络(Recurrent Neural Network, RNN)分别作为编码器和解码器。RNN的基本思想是当前时刻的状态受之前时刻的影响,因此理论上具有捕获全局上下文的能力,十分适合对变长的序列建模。在实际应用时,为了缓解RNN固有的梯度消失(Vanishing Gradient)问题,往往使用RNN的两个变种:长短时记忆网络(LSTM),门控循环单元(GRU)。但是RNN网络由于前后时刻存在时序上的依赖(即前一个时刻结束了,才能进行下一个时刻),因此无法并行计算,训练的时间代价很高。
以上就是机器翻译的三代的发展历史,技术的越来越先进。可以让机器翻译结果不断更好地满足用户的应用需求。通过学术界与企业界的联手推动,学术界注重机器翻译理论和技术创新,产业界侧重于机器翻译产品和应用创新,我们有充足的理由相信,当前机器翻译产业化正在迎来发展高潮,通过机器翻译帮助全球语言交流无障碍的时机已经来临。